Introducción
Swarm project
Este proyecto nació con la idea de reunificar servicios que actualmente están desperdigados entre diferentes máquinas virtuales (VM), además de modernizarlos y añadir otros que son necesarios actualmente.
Antes del sistema de contenedores, lo habitual era tener una máquina virtual para cada servicio (o múltiples), pero esto no siempre es eficiente debido a que, si no se utilizan todos los recursos, estos son desperdiciados. A eso se le suma el problema de incompatibilidad entre versiones: entre sistemas operativos, entre servicios y un gran etcétera. ¿Quién no ha tenido 2 aplicaciones con requisitos de versiones diferentes de PHP o Python e incompatibles entre ellas?
Por supuesto, el sistema de contenedores también tiene sus problemas (volúmenes, nada nuevo en un clúster), así que algunos servicios serán movidos hacia este nuevo clúster, y otros se mantendrán dónde est�án.
Este clúster utiliza Docker Swarm, actualmente todo se está moviendo hacia Kubernetes debido al gran nombre que está obteniendo y que los servicios cloud disponen de sus propias herramientas para desplegarlo, pero si nos fijamos, veremos que no siempre es tan bonito como no los pintan.
La gran ventaja de Kubernetes sobre el resto es su capacidad para desplegar más contenedores si uno de ellos se ha sobresaturado, y eliminarlos cuando ya no es necesario, a cambio Kubernetes nos implica una complejidad mayor y el problema de 'desperdiciar' al menos un nodo en hacerlo de manager (y si cae, el resto de los nodos no sirven de nada), este último se puede solucionar con variantes como K3s, pero la complejidad no tiene solución.
Por otro lado, Docker Swarm en un clúster pequeño es ideal, todos los nodos hacen de frontal, mientras un manager sobreviva (y todos pueden serlo), seguirá funcionando, con una configuración más simple.
Para hacer funcionar este proyecto, se requieren conocimientos previos de Docker y Docker Swarm, es posible que sin ellos sea complicado resolver o entender algunos problemas.
Especificaciones
Para este proyecto utilizaré 4 VM sobre un servidor basando en arquitectura Intel
Aunque muchos de los servicios que se van a desplegar pueden tener contenedores para ARM (utilizada por Raspberry), es posible que no siempre sea así, si se va a replicar esto en una arquitectura no-Intel, se deberá revisar cada servicio.
Esta es la lista de VM:
| Nombre | CPU | RAM | Disk1 | Disk2 |
|---|---|---|---|---|
| Database | 2 | 8 GiB | 20 GiB | 50 GiB |
| Swarm1 | 4 | 8 GiB | 100 GiB | 200 GiB |
| Swarm2 | 4 | 8 GiB | 100 GiB | 200 GiB |
| Swarm3 | 4 | 8 GiB | 100 GiB | 200 GiB |
El primer disco es utilizado para el sistema y el segundo para datos.
El nombre que he utilizado es para facilitar su lectura, como administrador de redes animo a poner nombres interesantes, no algo que describa su contenido, eso es aburrido y no aporta nada a la larga.
Un de ellas se dedicará en exclusiva a las bases de datos (MariaDB y PostgreSQL), mientras el resto serán parte del Docker Swarm.
Las bases de datos no estarán en contenedores debido a que no le veo sentido a ello, suponen un gran problema de gestión debido a que requieren acceso a disco constante para cualquier cosa, y ese es el punto débil de los contenedores.
Además de estas 4, se requiere un NAS o similar que pueda ofrecer acceso por NFS, este se utilizará para copias de seguridad y como storage de contenedores con cargas demasiado grandes.
Servicios
Este proyecto utiliza los servicios publicados por el Rasp Project, utilizaré su DNS, LDAP y Nagios.
La lista de servicios para este proyecto es grande, así que aquí únicamente voy a exponer la base, el resto se pueden encontrar en la sección dedicada a ello.
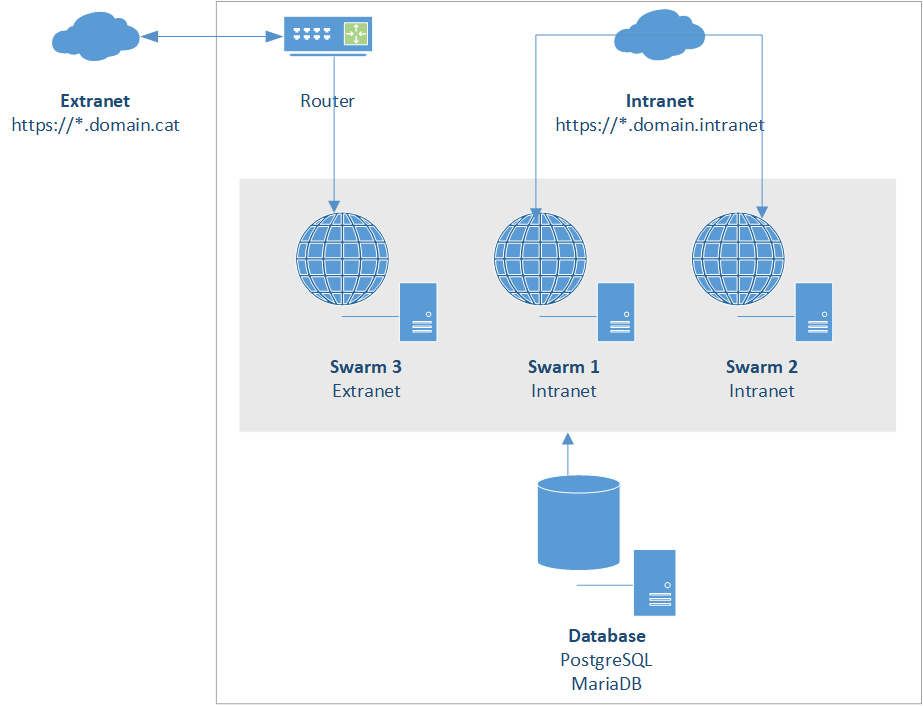
Algunos de estos servicios requieren estar publicados a Internet (Extranet) y otros únicamente deben estar en la Intranet, e incluso algunos deben estar en ambos lugares, debido a ello, reservaré un nodo para que publique los servicios de la Extranet y 2 para la Intranet, esto significa que, en caso de caer el nodo para la Extranet, todos los servicios publicados a Internet dejarán de estar accesibles. Esto puede solucionarse con un load-balancer o un router que se encargue de ello por sí mismo, yo no dispongo de ninguno ni está en mis planes obtenerlo, así que simplemente aceptaré ese problema.
Por supuesto, este mismo problema lo tiene la VM con las bases de datos, no existe una réplica de ellos, si cae, todos los servicios que lo requieren caerán.
Traefik
Una de las bases es que ningún servicio publicará un puerto para acceder a su web, todo será centralizado en un único proxy que también se encargará de la gestión de los certificados, ya que toda web debe tener HTTPS.
Durante años se ha utilizado o Apache o Nginx para esto, pero debido a que únicamente queremos hacer de proxy, Traefik es suficiente, este únicamente sabe hacer de proxy, no es capaz de publicar una web (como si hacen los anteriores), así que reducimos el consumo de memoria.
Portainer
En el proceso de simplificar, he optado por añadir una UI a Docker, en este caso Portainer ha sido la elegida, este nos permite gestionar prácticamente cualquier cosa desde ella.
ELK
Si algo tienen los contenedores, es que te puedes olvidar de los logs. Debido a su capacidad para destruirse y reconstruir, los logs se pierden.
Para solucionar este problema disponemos de ELK que son las siglas de Elastic Search - Logstash - Kibana, un kit de herramientas que permiten enviar logs a un motor de búsquedas y poder visualizarlas desde una UI.
Monitor
Con tantos servicios y servidores, necesitamos algo para controlar el rendimiento, y aunque disponemos de Nagios para las alertas, vamos a necesitar otro para comprobar que los contenedores y servidores estén como esperamos.
Para ello tenemos a Prometheus como núcleo donde almacenar la información y hacer las búsquedas, y Grafana para poderlas visualizar más fácilmente y crear los dashboards.
Keycloak
Disponemos de un LDAP, pero debido a que cada contenedor es independiente, al iniciar sesión en uno, este no se mantendrá en el resto y tendremos que volver a indicar nuestro usuario.
Para solucionar esto hay varias opciones, la más extendida seguramente sea OAuth2, para ello disponemos de Keycloak que nos permite exponer este y otros servicios, y ser conectado al LDAP, así cuando un servicio nos permita el uso de OAuth2, lo conectaremos directamente a este, si no es posible, tendremos que conectarlo al LDAP y aceptar que tendremos que iniciar sesión cada vez en él.
Otros
Como ya he indicado, esta no es la lista completa de servicios, otros tantos serán desplegados por este proyecto, y seguramente crecerá con el tiempo.
Repositorio
Todos los servicios son configurar con ficheros yaml y otros que sean requeridos por este, el ejemplo para todos ellos se encuentra en el repositorio de GitLab.
También es posible descargarlo en local para poderlo ajustar al servidor propio.
git clone https://gitlab.com/ReiIzumi/swarm-project.git